#15 分類コードをインデックスにする/Setting the Classification Code as the Index
An English translation of this article is provided at the bottom of the page.
前回の投稿では、産業連関表をデータフレーム形式で読み込むことに挑戦したのですが、
本当は、分類コード(文字列)をインデックスにしたいんですよね。どうやればいいんだろう…
というところで、時間切れを迎えてしまっていました。今回は、この続きから始めていきます。
列をインデックスにする
こちらのサイトを参考にしました。
列をインデックスにするための構文。dataframe.set_index(Column_name, inplace=True)
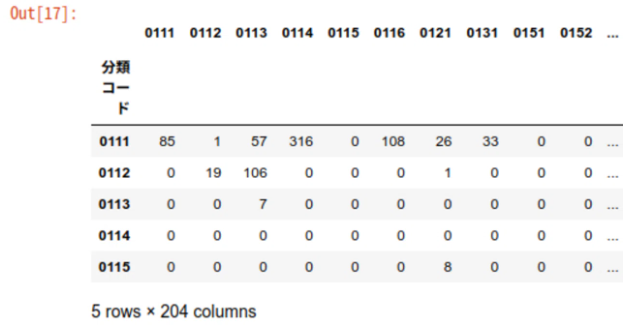
df_iotable.set_index('分類コード', inplace=True)
df_iotable.head()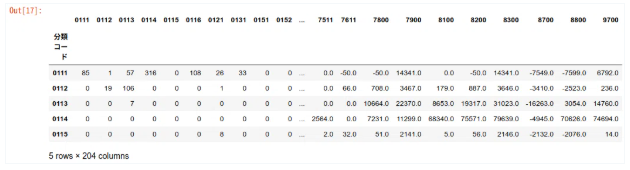
う〜ん。
本当は、列名のそれぞれが分類コードなので、列名の一つ上の階層にも、「分類コード」という階層を追加したほうがいいのかな?とも考えています。
でも、そうすると、インデックス名と重複するしなあ。
行インデックスの一つ上の階層を「分類コード(行)」、列インデックスの一つ上の階層を「分類コード(列)」とする方がいいのかな?
いろいろ迷うところはありますが、ひとまずこのまま次に進んでいくことにします。
おっと。
その前に、df_price_per_tonの方も、列「分類コード」をインデックスに設定しておくことにします。
df_price_per_ton.set_index('分類コード', inplace=True)
df_price_per_ton.head()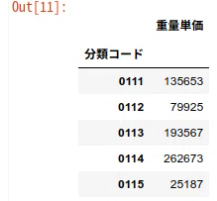
続いては、物質フローの推計になります。
物質フロー変換の算出式
投稿#6〜#12で推計を行った、各産業の重量単価【初期値】をもとに、産業連関表に記載されている金額フローを物質フローに変換し、産業廃棄物発生量を推計していきます。
算出式は、以下のようになります。
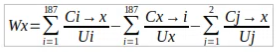
Uxについては、投稿#6で触れています。
Ux = Mx / Tx (2.1)
Ux : x産業の重量単価[円/t]
Mx : x産業の総生産額[円]
Tx : x産業の総生産量[t]
Wxの算出式を、Pythonの関数として定義することが必要かなと考えました。
今日はこの辺で。
English part is from here.
In my previous post, I challenged myself to load Input-Output (I-O) tables into a DataFrame format. However,
"I actually want to set the classification codes (strings) as the index. I wonder how I should do that..."
I ran out of time just at that point. Today, I’ll pick up right where I left off.
Setting a Column as the Index
I referred to this site for guidance.
Syntax for setting a column as the index:
dataframe.set_index(Column_name, inplace=True)
df_iotable.set_index('分類コード', inplace=True)
df_iotable.head()
Hmm. Since each of the column names is also a classification code, I’m considering whether it would be better to add a hierarchical level above the column names, perhaps titled "Classification Code."
But then, it would overlap with the index name.
Maybe it’s better to name the level above the row index "Classification Code (Row)" and the level above the column index "Classification Code (Column)"?
While there are several options to consider, for now, I’ll proceed as is.
Wait, before that, I should also set the "Classification Code" column as the index for df_price_per_ton.
df_price_per_ton.set_index('分類コード', inplace=True)
df_price_per_ton.head()
Next up is the estimation of material flows.
Calculation Formula for Material Flow Conversion
Based on the unit weight price (initial values) for each industry estimated in posts #6 through #12, I will convert the monetary flows listed in the I-O table into material flows and estimate the amount of industrial waste generated.
The calculation formula is as follows:
I mentioned Ux in post #6:
Ux = Mx / Tx (2.1)
Ux : Unit weight price of industry x [Yen/t]
Mx : Total production value of industry x [Yen]
Tx : Total production volume of industry x [t]
I think it might be necessary to define the calculation formula for Wx as a Python function.
That’s all for today.
Follow me!