#184 従業員数で産業廃棄物量を中分類から小分類へ按分
本研究において、産業廃棄物の統計データとして使用するのは、大阪府「大阪府産業廃棄物処理実態調査報告書(平成26年度実績)」になります。
上記の報告書は、産業廃棄物量を中分類で公表しています。本研究では、小分類別の重量単価を用いることを予定しているため、産業廃棄物量も小分類へ按分する必要があります。
今回は、橘ら(2012)に従い、従業員数で産業廃棄物量を中分類から小分類へ按分します。
按分方法には従業員数に基づ く方法と出荷額に基づく方法が挙げられる。産業か らの廃棄物発生量に対する各産業からの廃棄物発生 量の割合と,全産業の全従業員数に対する各産業の 従業員数の割合,並びに全産業の出荷額合計に対す る各産業の出荷額の割合を非類似度で比較したと ころ,従業員で按分したほうが全産業からの廃棄物 発生量に対する各産業からの廃棄物発生量の割合に 近いことがわかった。よって,本研究では従業員数 で廃棄物量を中・大分類から小分類へ按分した。
従業員推計用ワークシートの作成
統合小分類ごとに従業員を推計するワークシートを作成します。
VBAのコードは、以下のようになります。
code184-1
Sub 結合小分類毎に新規ワークシート作成()
' 結合小分類を読み込んで、部門1個毎に新規ワークシートを作成する
Dim bunruiCode As String
Dim bumonmei As String
Dim wbOrg As Worksheet
Dim wbDes AS Workbook
Dim wSheet As Worksheet
Dim i As Integer
Set wbOrg = Workbooks("H26大阪府結合小分類別従業員数一覧.ods").Worksheets("Sheet1")
Set wbDes = Workbooks("H26大阪府結合小分類別従業員数推計.ods")
For i = 2 To 112
bunruiCode = wbOrg.Cells(i, 1)
bumonmei = wbOrg.Cells(i, 2)
' 最後尾にシートを追加
Set wSheet = wbDes.Worksheets.Add(before:=Worksheets(Worksheets.Count))
' シート名を変更
wSheet.Name = bunruiCode
' 列名を入力
wSheet.Columns(1).NumberFormatLocal = "@"
wSheet.Columns(2).NumberFormatLocal = "@"
wSheet.Columns(5).NumberFormatLocal = "@"
wSheet.Columns(6).NumberFormatLocal = "@"
wSheet.RANGE("A1") = "細分類コード"
wSheet.RANGE("B1") = "細分類名"
wSheet.RANGE("C1") = "従業員数[人]"
wSheet.RANGE("E1") = "結合小分類コード"
wSheet.RANGE("E2") = bunruiCode
wSheet.RANGE("F1") = "産業部門名"
wSheet.RANGE("F2") = bumonmei
wSheet.RANGE("G1")= "従業員数[人]"
Next
End Sub統合小分類別の従業員数を算出
2014年(平成26年)大阪府における製造業の従業員数は、経済産業省「工業統計調査 確報 平成26年確報 表番号6-03 表題3 都道府県別産業細分類別統計表」からダウンロードしました。
また、小分類の各部門が細分類のどの範囲をカバーしているかは、総務省「平成23年(2011年)産業連関表(-総合解説編-)第3部 産業連関表で用いる部門分類表及び部門別概念・定義・範囲」を参考に判断しました。
本研究で用いる廃棄物量は、大阪府「大阪府産業廃棄物処理実態調査報告書(平成26年度実績)」における表2-1 業種別の発生及び処理・処分状況【平成26年度】に記載されている産業廃棄物の排出量となります。
中分類別産業廃棄物排出量を小分類へ按分
ここからの作業は、Pythonで行います。
産業廃棄物処理実態調査報告書のデータを読み込み
上述の産業廃棄物の排出量データをcsvファイルにし、データフレーム形式で読み込みます。
code184-2
import pandas as pd
# 産廃実態調査の排出量を読み込み
df_disposal = pd.read_csv("h26_osaka_disposal.csv", index_col=0)
# 有効数字を小数第一位にする
df_disposal = df_disposal.round(1)
# 列「従業員数」を追加
df_disposal["従業員数"] = 0
df_disposal.head()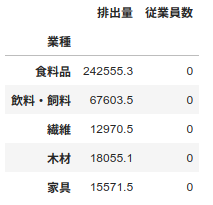
小分類別従業員数一覧のデータを読み込む
先に推計した、小分類別の従業員を一覧にしたcsvファイルをデータフレーム形式で読み込みます。その際、分類コード列を文字列に変換しておきます。
code184-3
# H26大阪府結合小分類別従業員数一覧を読み込み
df_employees = pd.read_csv("h26_manu_employees.csv")
# 分類コード列をデータ型を文字列に変換
df_employees['分類コード'] = df_employees['分類コード'].astype('str')
産業連関表と廃棄物実態調査の対応表をデータフレーム形式で読み込む
次に、産業連関表の小分類と産業廃棄物実態調査報告書の中分類との対応表をデータフレーム形式で読み込みます。
こちらも、分類コード列を文字列に変換しておきます。
code184-4
# 産業連関表と廃棄物実態調査の対応表をデータフレーム形式で読み込む
df_taiohyo = pd.read_csv('h26_taiohyo.csv')
# 分類コード列をデータ型を文字列に変換
df_taiohyo['分類コード'] = df_taiohyo['分類コード'].astype('str')
# 分類コードが3桁の場合、先頭に「0」をつける
for i in range(len(df_taiohyo)):
if len(df_taiohyo.loc[df_taiohyo.index[i], '分類コード']) == 3:
df_taiohyo.loc[df_taiohyo.index[i], '分類コード'] = '0' + str(df_taiohyo.loc[df_taiohyo.index[i], '分類コード'])小分類別従業員数一覧と対応表をマージ
小分類別従業員数一覧と対応表を分類コード列をもとに、マージします。マージした後に、新規列「排出量」を追加します。
code184-5
# H26大阪府結合小分類別従業員数一覧と対応表をマージ
df_code_disposal = pd.merge(df_employees, df_taiohyo, on="分類コード", how="left")
df_code_disposal = df_code_disposal.set_index("分類コード")
# df_code_disposalに列「排出量」を追加
df_code_disposal["排出量"] = 0
df_code_disposal.head()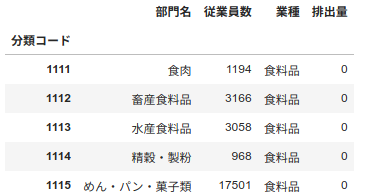
中分類別従業員数を算出
中分類別の従業員数を算出します。
code184-6
# 中分類業種別従業員数の算出
for sect in df_disposal.index:
df_disposal.loc[sect, "従業員数"] = df_code_disposal.pivot_table(index="業種", aggfunc=sum).loc[sect, "従業員数"]
df_disposal.head()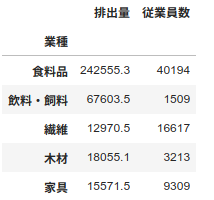
中分類別排出量を従業員数で小分類へ按分
code184-6における中分類別従業員数のデータフレームと、code184-3における小分類別従業員数一覧のデータフレームより、従業員数で排出量を小分類へ按分します。
code184-6
# 排出量を従業員数で小分類へ按分
for code in df_code_disposal.index:
sect = df_code_disposal.loc[code, "業種"]
df_code_disposal.loc[code, "排出量"] = (df_disposal.loc[sect, "排出量"] * df_code_disposal.loc[code, "従業員数"]
/ df_disposal.loc[sect, "従業員数"]
).round(1)
df_code_disposal.head()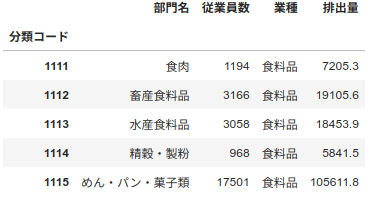
Follow me!

